Human-LLM Collaborative Annotation Through Effective Verification of LLM Labels
It’s fascinating how large language models (LLMs) have revolutionized natural language processing (NLP) tasks. Their performances are truly remarkable, suggesting they could be game-changers across many tasks, including annotating data faster and cheaper than humans. But sometimes, LLMs make mistakes, e.g., when inputs are complex, or tasks are domain-specific. They may even introduce biases into training data.
So, what’s the solution? The answer is collaboration! Instead of completely replacing human annotators with LLMs, we need to leverage the strengths of both sides to obtain accurate and reliable annotations. This article will discuss how to effectively utilize LLMs as collaborators for data annotation.
Human-LLM Collaborative Annotation Framework

We propose a multi-step human-LLM collaborative framework for data annotation to ensure accuracy and trustworthiness. First, LLMs predict labels and generate explanations. Next, a trained verifier model assesses LLM labels and explanations. Finally, human annotators re-annotate a subset of labels that have the lowest verifier scores.
The key differentiating idea here is utilizing LLMs’ self-explanation capability to explain their labeling decisions. In Step 2, the LLM-generated explanations can provide more information on LLMs’ reasoning processes for the verifier model [Marasovic et al., 2022]. In the human re-annotation step, LLM explanations can help human annotators to understand and trust LLMs as collaborators [Wang et al., 2023].
To achieve effective collaboration in such a framework, we explore two research questions in our CHI 2024 paper.
- RQ1: How can we verify LLM-generated labels using signals from inputs, LLM labels, and LLM explanations?
- RQ2: Does providing LLM-generated labels and explanations help humans in re-annotation?
In the following, we will discuss the above questions in detail.
Verifier: Experiments and Results
We developed a verifier model that assigns scores to LLM-generated labels. The scores can help identify a subset of potentially erroneous labels to avoid wasting human efforts re-annotating already correct LLM labels.
LLMs take text samples as the input and generate labels and explanations as the output. We collected features from these three dimensions along the LLM annotation process. In total, we ended up with 70 input features (e.g., text characteristic features and sample representative features such as coherence, perplexity, and readability), 7 label features (e.g., logit and entropy), and 73 explanation features (e.g., explanation sufficiency, simulatability).
We performed experiments using different settings across various datasets. Results show that our verifier better identifies incorrect LLM labels than a logit-based baseline, widely used to estimate LLMs’ uncertainty. This means that additional signals from input and explanation are useful in distinguishing potentially incorrect LLM labels.


Human Re-annotation: Human-Subject Study and Results
In the re-annotation step, humans label a subset of LLM labels suggested by the verifier in the previous step.
We conducted a human-subject study to identify the optimal strategy for enhancing human re-annotation performance: (1) not presenting any LLM model’s outputs to human annotators, (2) presenting only the LLM-generated labels, and (3) presenting both the LLM-generated labels and the explanations.



Figure 3: Task interface used in the human-subject study for different re-annotation strategies.
For each data point, participants reviewed the data with or without LLM assistance, and then provided their final annotations (Figure 3).
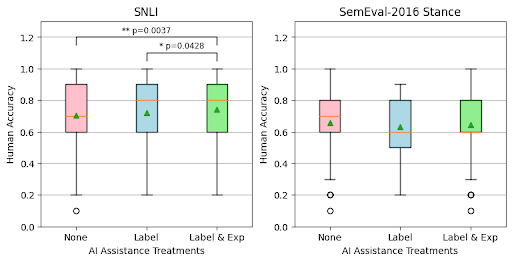
For the SNLI dataset, human accuracy was higher when providing both LLM labels and explanations than when only providing LLM labels or without any assistance. On the other hand, results on the stance detection task did not show any statistically significant differences between AI assistance treatments.
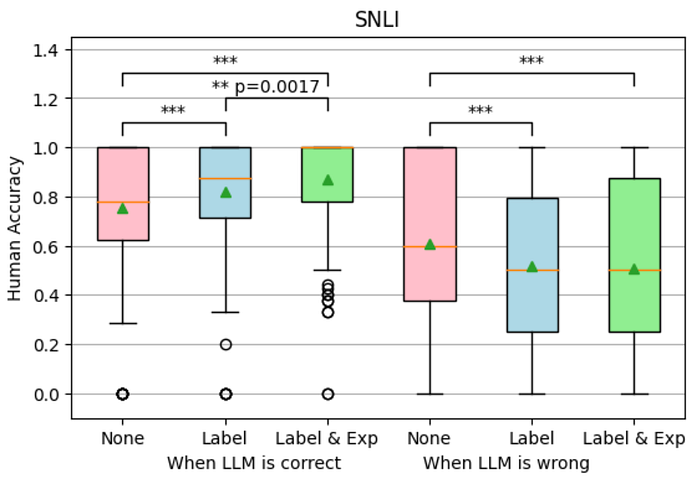
We further analyzed if the effect of LLM assistance differed on LLM correct instances and LLM wrong instances. We found that when LLM was correct, the participants were more accurate with more LLM assistance. Interestingly, when LLM was incorrect, providing the wrong LLM labels hurt human accuracy. There were no differences between showing both the LLM explanation and label, and showing only the LLM label.
For more details on study setup and additional human perception analyses, please refer to our CHI 2024 paper.
Takeaways
We discussed how to design LLM-human collaborative annotation frameworks by leveraging a LLM’s label and self-explanation in automatic verification and re-annotation. Our findings from the verifier experiments suggest that different signals such as self-explanations can be informative when automatically verifying LLM-generated annotations — i.e., do not solely rely on logits. The crowdsourced study calls for the need to quantify and improve the quality of LLM explanations and carefully decide when explanations are helpful for human re-annotation.
Try our LLM Annotation Tool!
With this research and ML practitioners in mind, we have built MEGAnno, an annotation tool that uses human-LLM collaboration with verification. Try it!

Article written by: Hannah Kim and Megagon Labs.
